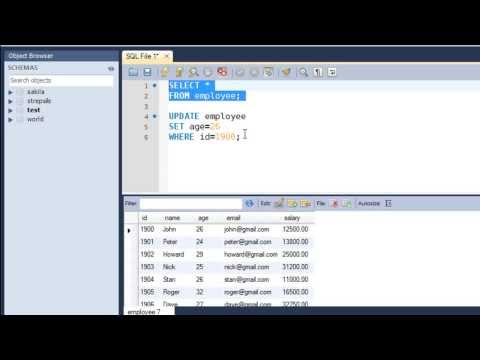
For the single-table syntax, the UPDATE statement updates columns of existing rows in the named table with new values. The SET clause indicates which columns to modify and the values they should be given. Each value can be given as an expression, or the keyword DEFAULT to set a column explicitly to its default value. The WHERE clause, if given, specifies the conditions that identify which rows to update. If the ORDER BY clause is specified, the rows are updated in the order that is specified. The LIMIT clause places a limit on the number of rows that can be updated.

The UPDATE JOIN is a MySQL statement used to perform cross-table updates that means we can update one table using another table with the JOIN clause condition. This query update and alter the data where more than one tables are joined based on PRIMARY Key and FOREIGN Key and a specified join condition. We can update single or multiple columns at a time using the UPDATE query. If LOW_PRIORITY is provided, the update will be delayed until there are no processes reading from the table. LOW_PRIORITY may be used with MyISAM, MEMORY and MERGE tables that use table-level locking.

If IGNORE is provided, all errors encountered during the update are ignored. If an update on a row would result in a violation of a primary key or unique index, the update on that row is not performed. Expression1, expression2 The new values to assign to the column1, column2. So column1 would be assigned the value of expression1, column2 would be assigned the value of expression2, and so on. The conditions that must be met for the update to execute.

It may be used in combination with LIMIT to sort the records appropriately when limiting the number of records to be updated. If LIMIT is provided, it controls the maximum number of records to update in the table. At most, the number of records specified by number_rows will be update in the table. A SQL UPDATE query is used to alter, add, or remove data within some or alltuplesin existing rows of a table. In the typical format, we usually update one tuple at a time in a table.

We can also update multiple tuples at a time when we make use of the WHERE clause. Alternatively, we can update all the tuples in a column with a simple UPDATE statement. However, in the later scenario, all the rows will have the same value in that column. Now, what if you want to update all the tuples in one or more columns of a table with unique corresponding values in another table. Our simple UPDATE TABLE NAME SET COLUMN NAMES statement will not work in this scenario.

Okay, actually it will, but it would be a long tedious script when you are working with a few hundred or a few thousand rows of data. SQL gives users the option to update existing records in tables with the help of the UPDATE command. Using this command, you can change and alter some of the records from single or multiple columns of a table. We typed the table name, which will be updated after the UPDATE statement.
After the SET keyword, we specified the column names to be updated, and also, we matched them with the referenced table columns. After the FROM clause, we retyped the table name, which will be updated. After the INNER JOIN clause, we specified the referenced table and joined it to the table to be updated.

In addition to this, we can specify a WHERE clause and filter any columns of the referenced or updated table. We can also rewrite the query by using aliases for tables. Second, the merge_condition determines how the rows from the source table are matched to the rows from the target table.
Typically, you use the key columns either primary key or unique key for matching. One thing you will notice that is different in this sample as opposed to the previous two, is this one is actually two different scripts that are independent of each other. Unfortunately, SQL does not allow more than one SET condition per query. The UPDATE statement lists the target table, the SET statement specifies the column on that target table and the SELECT statement lists the source table and column. In this scenario, we use a WHERE clause to link the two tables via a common column. In this guide, we've taken a look at the basic ways that you can modify existing data within a table using the UPDATE command.

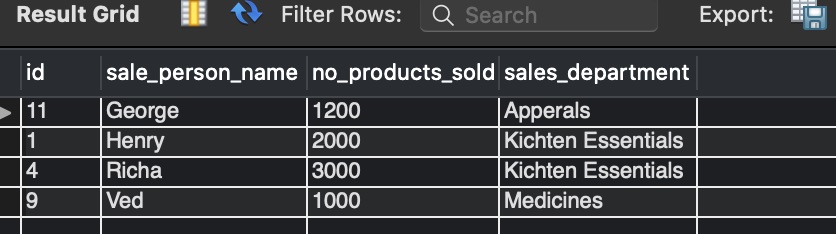
The UPDATE command is essential for managing your data after its initial ingestion into your databases. The query checks the performance column values for each row in the "Employees" table against the performance column of the "Performance" table. If it will get the matched performance column, then it takes the percentage in the Performance table and updates the Employees table's salary column. This query updates all records in the Employees table because we have not specified the WHERE clause in the UPDATE JOIN query.
In this method, the table to be updated will be joined with the reference table that contains new row values. So that, we can access the matched data of the reference table based on the specified join type. Lastly, the columns to be updated can be matched with referenced columns and the update process changes these column values.

An UPDATE query is used to change an existing row or rows in the database. UPDATE queries can change all tables' rows, or we can limit the update statement affects for certain rows with the help of the WHERE clause. Mostly, we use constant values to change the data, such as the following structures. For partitioned tables, both the single-single and multiple-table forms of this statement support the use of a PARTITION clause as part of a table reference.

This option takes a list of one or more partitions or subpartitions . Note that the difference between the ROWS_PARSED and ROWS_LOADED column values represents the number of rows that include detected errors. However, each of these rows could include multiple errors. To view all errors in the data files, use the VALIDATION_MODE parameter or query the VALIDATE function.

However, you also may want to consider the performance cost of the option you choose from this SQL tutorial. On this simple example, the performance cost is minimal regardless of which option you select. We could take it a step further by adding a WHERE clause to filter out any columns from the referenced or updated tables. This will allow for updating only certain rows while leaving the other rows untouched. With the SET keyword, we specified which columns in the target table we want updated and set them to equal the values found in the source table, matching the columns by aliases. Finally, we linked the source and target tables via an INNER JOIN by using the matching BusinessEntityID and AddressID columns respectively from each table.

The optional RETURNING clause causes UPDATE to compute and return value based on each row actually updated. Any expression using the table's columns, and/or columns of other tables mentioned in FROM, can be computed. The new (post-update) values of the table's columns are used. The syntax of the RETURNING list is identical to that of the output list of SELECT. An SQL UPDATE statement changes the data of one or more records in a table. Either all the rows can be updated, or a subset may be chosen using a condition.

The COPY operation verifies that at least one column in the target table matches a column represented in the data files. If a match is found, the values in the data files are loaded into the column or columns. If no match is found, a set of NULL values for each record in the files is loaded into the table. DefinitionDefines the encoding format for binary string values in the data files. The option can be used when loading data into binary columns in a table. When transforming data during loading (i.e. using a query as the source for the COPY command), this option is ignored.
There is no requirement for your data files to have the same number and ordering of columns as your target table. In this tutorial, we will explore three options that will update all the tuples in one or more columns with unique values that are stored in a separate table. Remember, you will need to make sure that the columns you are updating are of the same or compatible datatypes as the source columns. Example, you cannot put a VARCHAR value in an INT field. Using multiple tables to update the source table is a common requirement.
The Snowflake update command does not support join clause. So, the other workaround would be to create sub query within the FROM clause. If the subquery finds a matching row, the update query updates the records for the specific employee. In the database world, static data is not typically stored. Instead, it keeps changing when we update existing data, archive or delete irrelevant data and more. For example, let's say you have a table that stores product pricing data for your shopping portal.

The product prices constantly change, as you might offer product discounts at different times to your customers. In this case, you cannot add new rows in the table because the product record already exists, but you are required to update the current prices for existing products. The subquery method is the very basic and easy method to update existing data from other tables' data. The noticeable difference in this method is, it might be a convenient way to update one column for the tables that have a small number of the rows. Now we will execute the following query and then will analyze it. Now, if we go back to our position, the MERGE statement can be used as an alternative method for updating data in a table with those in another table.

In this method, the reference table can be thought of as a source table and the target table will be the table to be updated. The following query can be an example of this usage method. However, for different scenarios, this constant value usage type cannot be enough for us, and we need to use other tables' data in order to update our table. This type of update statement is a bit complicated than the usual structures. In the following sections, we will learn how to write this type of update query with different methods, but at first, we have to prepare our sample data.
To do a conditional update depending on whether the current value of a column matches the condition, you can add a WHERE clause which specifies this. The database will first find rows which match the WHERE clause and then only perform updates on those rows. The source table has some rows with the same keys as the rows in the target table.

However, these rows have different values in the non-key columns. In this case, you need to update the rows in the target table with the values coming from the source table. Specifies an existing named file format to use for loading/unloading data into the table.

The named file format determines the format type (CSV, JSON, etc.), as well as any other format options, for data files. The MERGE statement is used to manipulate a target table by referencing a source table for the matched and unmatched rows. The MERGE statement can be very useful for synchronizing the target table with data from any source table that has the correct corresponding data and datatypes. Since each tuple in each row is unique, we could use the standard form "update – set" method, but that would take too long since it will have to be done one row at a time. You can use the subquery to update the data from another table. The following UPDATE statement will update the Salary in the Consultant table by selecting Salary from the Employee table for the matching EmpId values.

Before updating any of the records, it is important to check the data types of all columns. Additionally, if any of the columns have constraints (i.e."Primary Key" and "NOT NULL"), the values need to be updated accordingly. You can use any method specified in this article for performing UPDATE from SELECT statements. The subquery works efficiently, but it has its own limitations, as highlighted earlier. The overall performance of your database depends on the table data, the number of updates, table relationships,indexes, and statistics.

The subquery with a comparison operator can include only one column name except if it used for the IN or EXISTS operator. Therefore, if we require updating multiple columns of data, we need separate SQL statements. The subquery defines an internal query that can be used inside a SELECT, INSERT, UPDATE andDELETE statement.

It is a straightforward method to update the existing table data from other tables. The MERGE statement is useful for manipulating data in the target table based on the source table data for both matched and unmatched rows. It is an alternative method for performing the UPDATE from the SELECT statement function. This method usesSQL Joinsfor referencing the secondary table that contains values that need to be updated. Therefore, the target table gets updated with the reference columns data for the specified conditions. In this article, we will see, how to update from one table to another table based on ID match.

The update statement is always followed by the SET command. The SET command is used to specify which columns and values need to be updated in a table. In this last line of the query, we chose the manipulation method for the matched rows. Individually for this query, we have selected the UPDATE method for the matched rows of the target table. Finally, we added the semicolon (;) sign because the MERGE statements must end with the semicolon signs. The Index Update and Sort operators consume 74% cost of the execution plan.

We have seen this obvious performance difference between the same query because of index usage on the updated columns. As a result, if the updated columns are being used by the indexes, like this, for example, the query performance might be affected negatively. In particular, we should consider this problem if we will update a large number of rows.

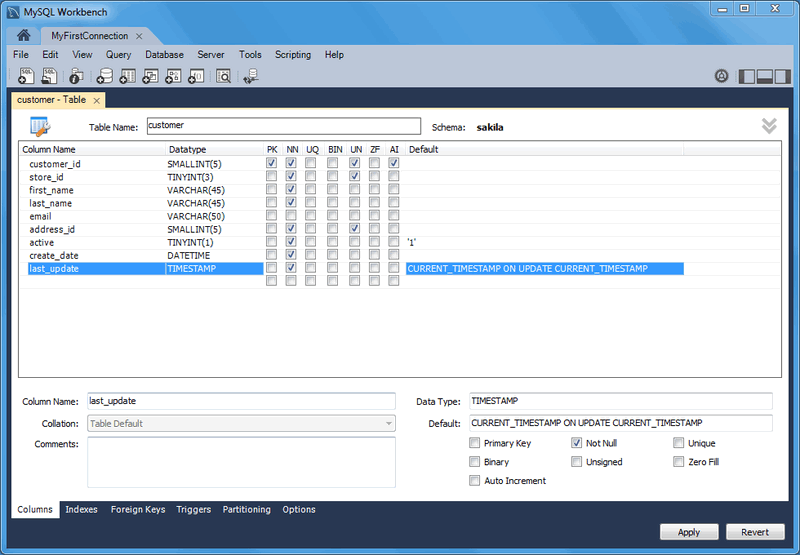
To overcome this issue, we can disable or remove the index before executing the update query. (For storage engines such as InnoDB that employ row-level locking, no locking of partitions takes place.) For more information, see Section 19.6.4, "Partitioning and Locking". The MySQL UPDATE statement is used to update columns of existing rows in a table with new values. The SQL Server (Transact-SQL) UPDATE statement is used to update existing records in a table in a SQL Server database. There are 3 syntaxes for the UPDATE statement depending on whether you are performing a traditional update or updating one table with data from another table. When using FROM, one should ensure that the join produces at most one output row for each row to be modified.
In other words, a target row shouldn't join to more than one row from the other table. If it does, then only one of the join rows will be used to update the target row, but which one will be used is not readily predictable. Now that you know how to update existing records, it's time for you to start querying and manipulating this updated and existing data in different datasets. This is an essential step to moving forward in your journey to becoming an SQL expert. If you liked this article, and want to get certified, check out Simplilearn's Business Analyst Master's Program. This comprehensive program covers SQL in-depth, and earning your certification in this field can help to jumpstart your career.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.